TaiChi-HD

Given a start frame and a set of strokes, MCDiff synthesizes a video matching the desired motion while preserving the content.
Recent advancements in diffusion models have greatly improved the quality and diversity of synthesized content. To harness the expressive power of diffusion models, researchers have explored various controllable mechanisms that allow users to intuitively guide the content synthesis process. Although the latest efforts have primarily focused on video synthesis, there has been a lack of effective methods for controlling and describing desired content and motion.
In response to this gap, we introduce MCDiff, a conditional diffusion model that generates a video from a starting image frame and a set of strokes, which allow users to specify the intended content and dynamics for synthesis. To tackle the ambiguity of sparse motion inputs and achieve better synthesis quality, MCDiff first utilizes a flow completion model to predict the dense video motion based on the semantic understanding of the video frame and the sparse motion control. Then, the diffusion model synthesizes high-quality future frames to form the output video.
We qualitatively and quantitatively show that MCDiff achieves the state-the-of-art visual quality in stroke-guided controllable video synthesis. Additional experiments on MPII Human Pose further exhibit the capability of our model on diverse content and motion synthesis.
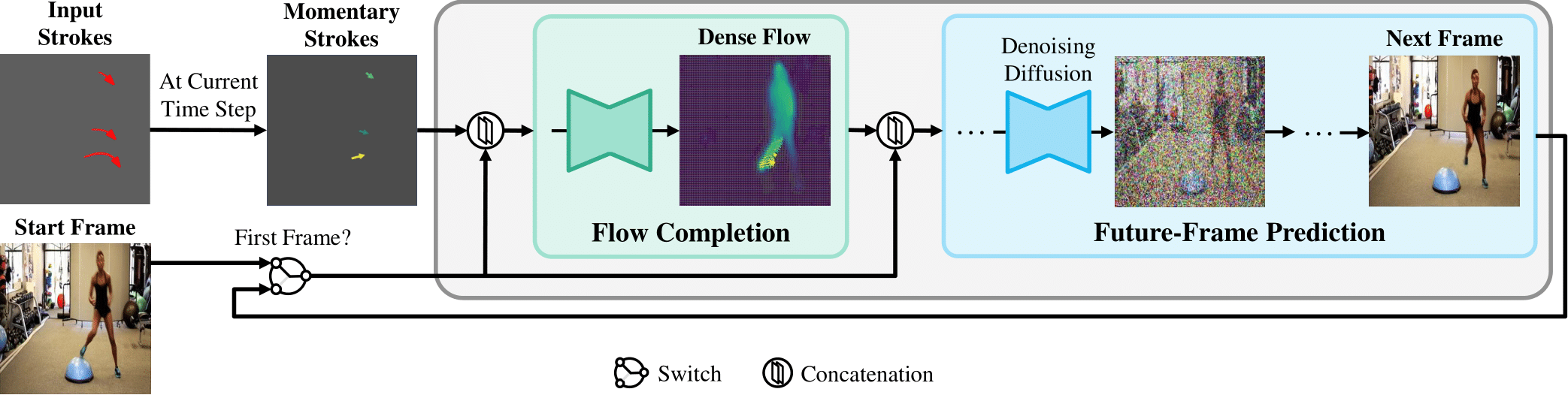
MCDiff is an autoregressive video synthesis model. For each time step, the model is guided by the previous frame (i.e., start or previously predicted frame) and the momentary segment of input strokes. Our flow completion model first predicts dense flows representing per-pixel momentary motion. Then, the future-frame prediction model synthesizes the next frame based on the previous frame and the predicted dense flow through a conditional diffusion process.
We compare MCDiff with iPOKE, the state-of-the-art stroke-guided controllable video synthesis. We input two models with the same start frames and strokes to control the subjects' noses, elbows, and knees. The expected destinations of the controlled points are marked at the end frames (red crosses). MCDiff can synthesize the videos with better quality while more faithfully following the motions specified by the strokes.
TaiChi-HD
Human3.6M
@article{chen2023mcdiff,
title = {Motion-Conditioned Diffusion Model for Controllable Video Synthesis},
author = {Chen, Tsai-Shien and Lin, Chieh Hubert and Tseng, Hung-Yu and Lin, Tsung-Yi and Yang, Ming-Hsuan},
journal = {arXiv preprint arXiv:2304.14404},
year = {2023},
}